Real Time Concert Ticket Recommendations with Rockset

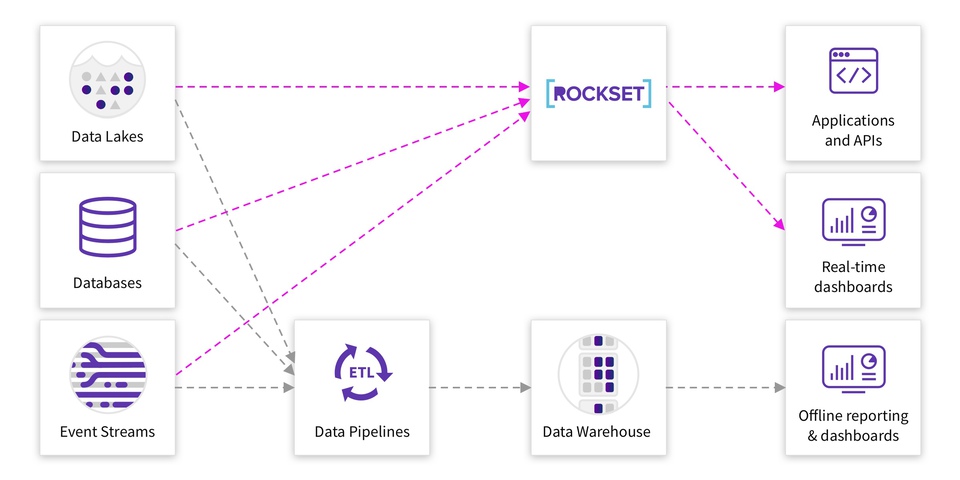
When building data-driven applications, it’s been a common practice for years to move analytics away from the source database into either a slave, data warehouse or something similar. The main reason for this is that analytical queries, such as aggregations and joins, tend to require a lot more resources. When running, the detrimental impact on database performance could reverberate back to front-end users and have a negative impact on their experience.
Analytical queries tend to take longer to run and use more resources because firstly they are performing calculations on large data sets and also potentially joining lots of data sets together. Furthermore, a data model that works for fast storage and retrieval of single rows probably won’t be the most performant for large analytical queries.
To alleviate the stress on the main database, data teams often replicate data to an external database for running analytical queries. Personally, with MongoDB, moving data to a SQL-based platform is extremely beneficial for analytics. Most data practitioners understand how to write SQL queries, however MongoDB’s query language isn’t as intuitive so will take time to learn. On top of this, MongoDB also isn’t a relational database so joining data isn’t trivial or that performant. It therefore would be beneficial to perform any analytical queries that require joins across multiple and/or large datasets elsewhere.
To this end, Rockset has partnered with MongoDB to release a MongoDB-Rockset connector. This means that data stored in MongoDB can now be instantly indexed in Rockset through a built-in connector. In this post I’m going to explore the use cases for using a platform like Rockset for your aggregations and joins on MongoDB data and walk through setting up the integration so you can get up and running yourself.
Recommendations API for an Online Event Ticketing System
To explore the benefits of replicating a MongoDB database into an analytics platform like Rockset, I’ll be using a simulated event ticketing website. MongoDB is used to store weblogs, ticket sales and user data. Online ticketing systems can often have a very high throughput of data in short time frames, especially when sought after tickets are released and thousands of people are all trying to purchase tickets at the same time.
It is therefore expected that a scaleable, high-throughput database like MongoDB would be used as the backend to such a system. However, if we are also trying to surface real-time analytics on this data, this could cause performance issues especially when dealing with a spike in activity. To overcome this, I’ll use Rockset to replicate the data in real time to allow computational freedom on a separate platform. This way, MongoDB is free to deal with the large volume of incoming data, whilst Rockset handles the complex queries for applications, such as making recommendations to users, dynamic pricing of tickets, or detecting anomalous transactions.
I’ll run through connecting MongoDB to Rockset and then show how you can build dynamic and real-time recommendations for users that can be accessed via the Rockset REST API.
Connecting MongoDB to Rockset
The MongoDB connector is currently available for use with a MongoDB Atlas cluster. In this article I’ll be using a MongoDB Atlas free tier deployment, so make sure you have access to an Atlas cluster if you are going to follow along.
To get started, open the Rockset console. The MongoDB connector can be found within the Catalog, select it and then click the Create Collection button followed by Create Integration.
As mentioned earlier, I’ll be using the fully managed MongoDB Atlas integration highlighted in Fig 1.
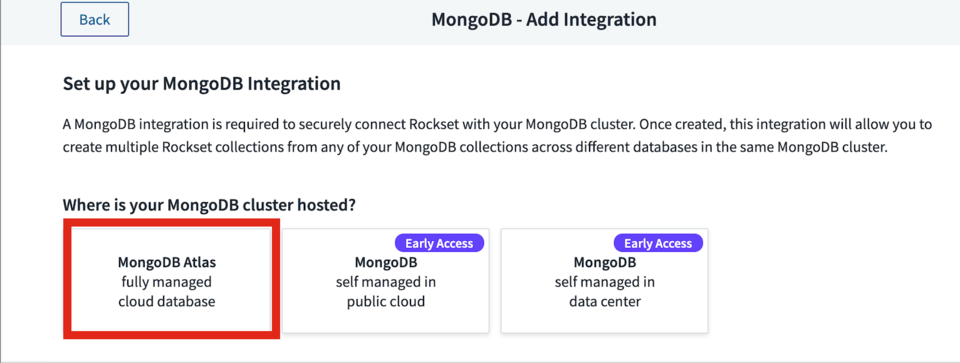 Fig 1. Adding a MongoDB integration
Fig 1. Adding a MongoDB integration
Just follow the instructions to get your Atlas instance integrated with Rockset and you’ll then be able to use this integration to create Rockset collections. You may find you need to tweak a few permissions in Atlas for Rockset to be able to see the data, but if everything is working, you’ll see a preview of your data whilst creating the collection as shown in Fig 2.
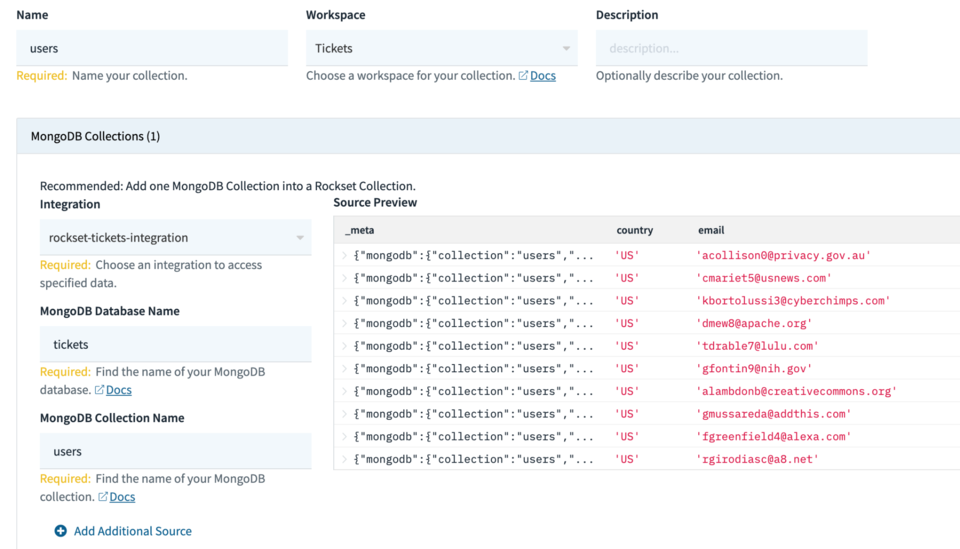
Fig 2. Creating a MongoDB collection
Using this same integration I’ll be creating 3 collections in total: users, tickets and logs. These collections in MongoDB are used to store user data along with favourite genres, ticket purchases and weblogs respectively.
After creating the collection, Rockset will then fetch all the data from Mongo for that collection and give you a live update of how many records it has processed. Fig.3 shows the initial scan of my logs table reporting that it has found 4000 records but 0 have been processed.
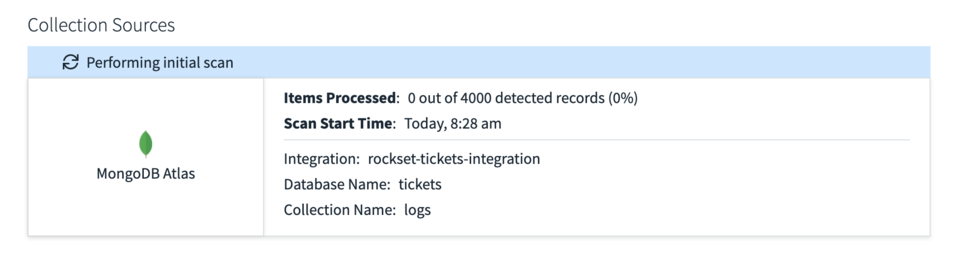 Fig 3. Performing initial scan of MongoDB collection
Fig 3. Performing initial scan of MongoDB collection
Within just a minute all 4000 records were processed and brought into Rockset, as new data is added or updates are made, Rockset will reflect them in the collection too. To test this out I simulated a few scenarios.
Testing the Sync
To test the syncing capability between Mongo and Rockset I simulated some updates and deletes on my data to check they were synced correctly. You can see the initial version of the record in Rockset in Fig 4.
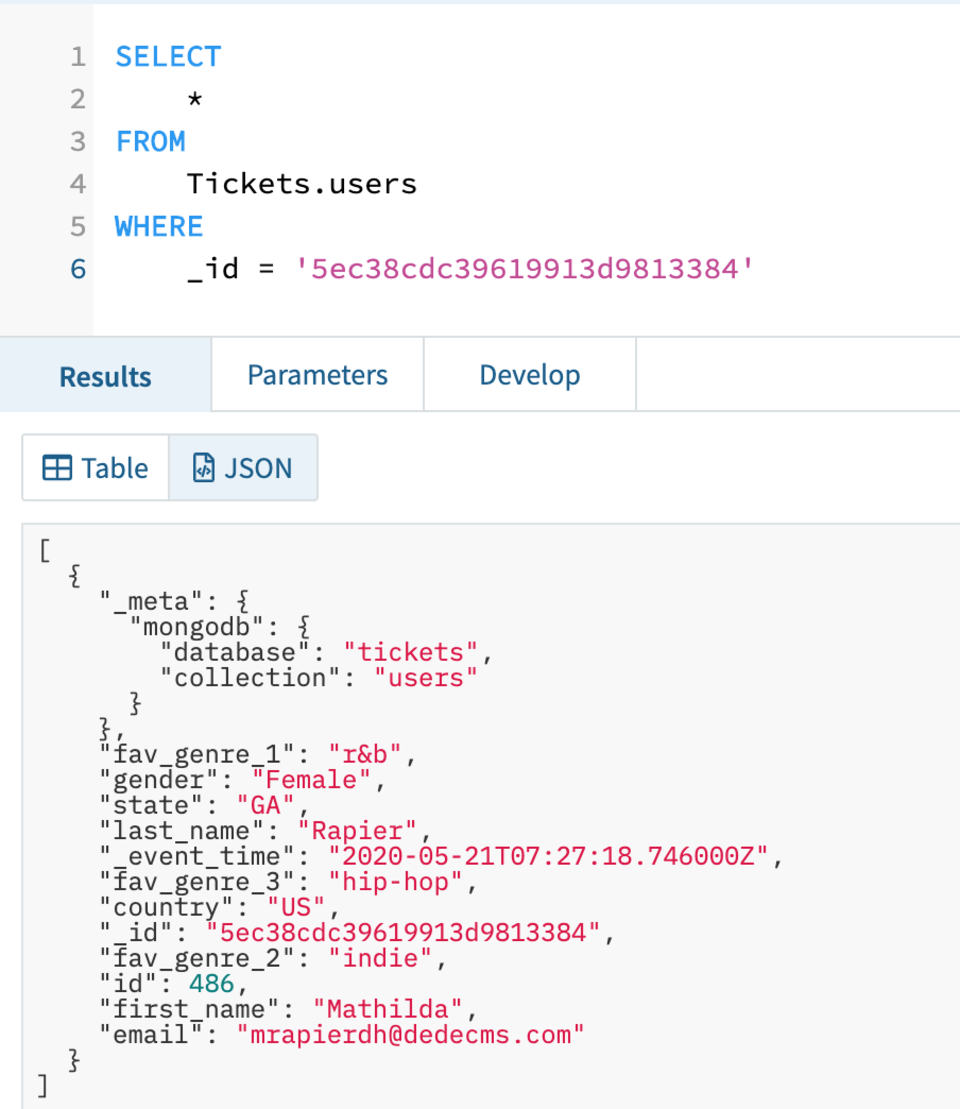 Fig 4. Example user record before an update
Fig 4. Example user record before an update
Now let’s say that this user changes one of their favourite genres, let’s say fav_genre_1 is now ‘pop’ instead of ‘r&b’. First I’ll perform the update in Mongo like so.
db.users.update({"_id": ObjectId("5ec38cdc39619913d9813384")}, { $set: {"fav_genre_1": "pop"} } )
Then run my query in Rockset again and check to see if it has reflected the change. As you can see in Fig 5, the update was synced correctly to Rockset.
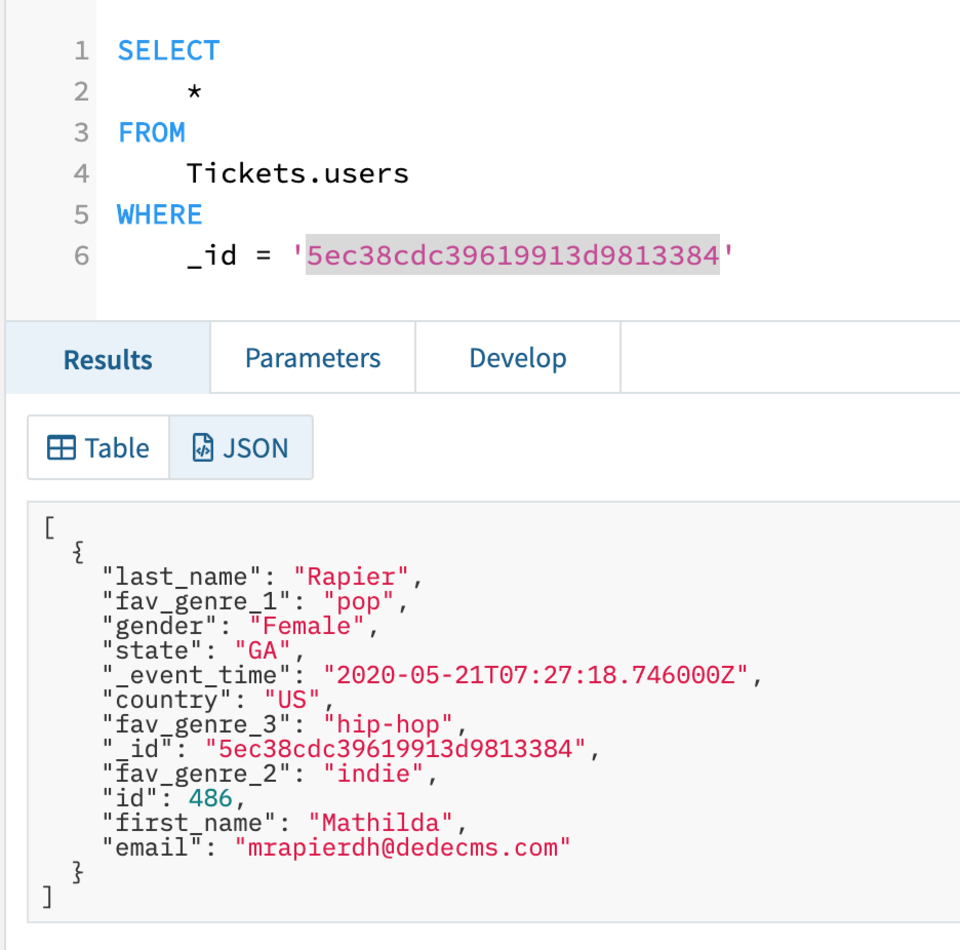 Fig 5. Updated record in Rockset
Fig 5. Updated record in Rockset
I then removed the record from Mongo and again as shown in Fig 6 you can see the record now no longer exists in Rockset.
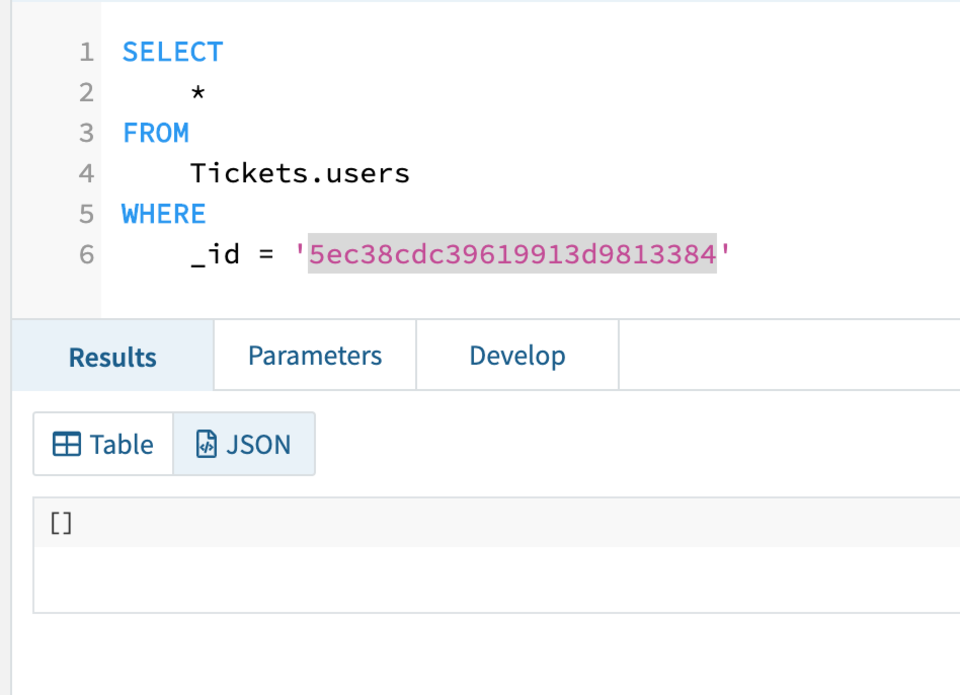 Fig 6. Deleted record in Rockset
Fig 6. Deleted record in Rockset
Now we’re confident that Rockset is correctly syncing our data, we can start to leverage Rockset to perform analytical queries on the data.
Composing Our Recommendations Query
We can now query our data within Rockset. We’ll start in the console and look at some examples before moving on to using the API.
We can now use standard SQL to query our MongoDB data and this brings one notable benefit: the ability to easily join datasets together. If we wanted to show the number of tickets purchased by users, showing their first and last name and number of tickets, in Mongo we’d have to write a fairly lengthy and complicated query, especially for those unfamiliar with Mongo query syntax. In Rockset we can just write a straightforward SQL query.
SELECT users.id, users.first_name as "First Name", users.last_name as "Last Name", count(tickets.ticket_id) as "Number of Tickets Purchased"
FROM Tickets.users
LEFT JOIN Tickets.tickets ON tickets.user_id = users.id
GROUP BY users.id, users.first_name, users.last_name
ORDER BY 4 DESC;
With this in mind, let’s write some queries to provide recommendations to users and show how they could be integrated into a website or other front end.
First we can develop and test our query in the Rockset console. We’re going to look for the top 5 tickets that have been purchased for a user’s favourite genres within their state. We’ll use user ID 244 for this example.
SELECT
u.id,
t.artist,
count(t.ticket_id)
FROM
Tickets.tickets t
LEFT JOIN Tickets.users u on (
t.genre = u.fav_genre_1
OR t.genre = u.fav_genre_2
OR t.genre = u.fav_genre_2
)
AND t.state = u.state
AND t.user_id != u.id
WHERE u.id = 244
GROUP BY 1, 2
ORDER BY 3 DESC
LIMIT 5
This should return the top 5 tickets being recommended for this user.
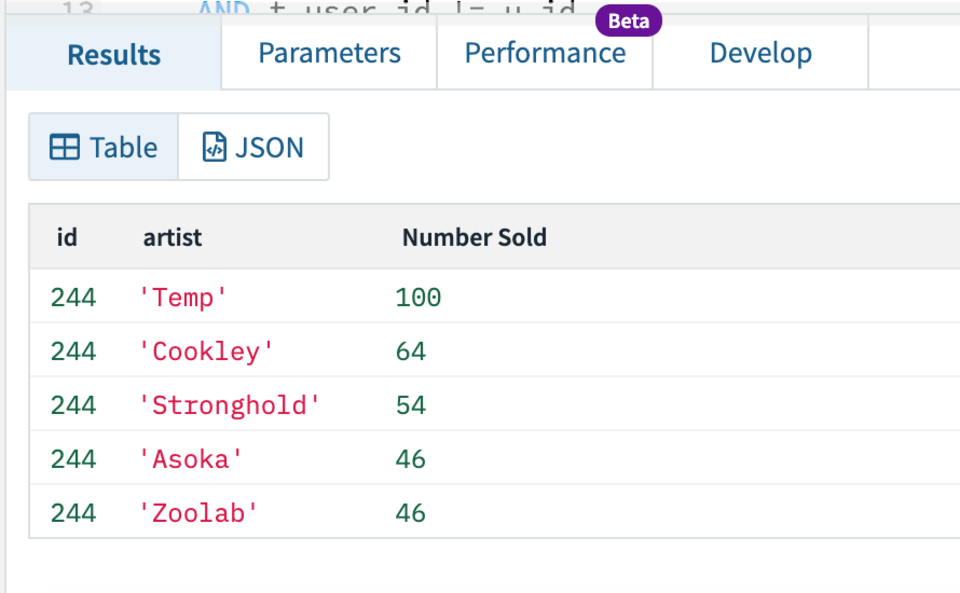 Fig 7. Recommendation query results
Fig 7. Recommendation query results
Now obviously we want this query to be dynamic so that we can run it for any user, and return it back to the front end to be displayed to the user. To do this we can create a Query Lambda in Rockset. Think of a Query Lambda like a stored procedure or a function. Instead of writing the SQL every time, we just call the Lambda and tell it which user to run for, and it submits the query and returns the results.
First thing we need to do is prep our statement so that it is parameterised before turning it into a Query Lambda. To do this select the Parameters tab above where the results are shown in the console. You can then add a parameter, in this case I added an int parameter called userIdParam as shown in Fig 8.
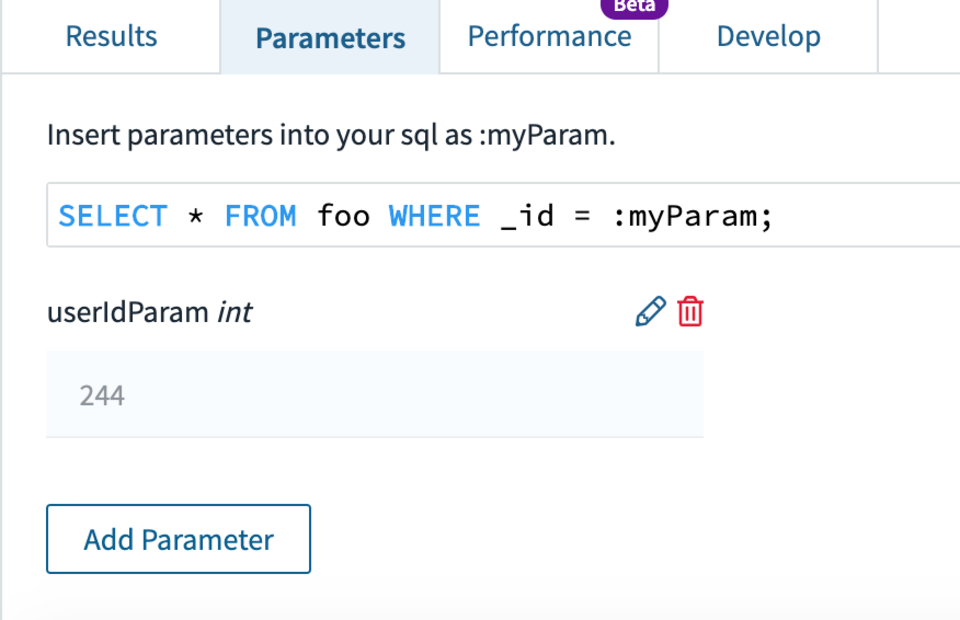 Fig 8. Adding a user ID parameter
Fig 8. Adding a user ID parameter
With a slight tweak to our where clause shown in Fig 9 we can then utilise this parameter to make our query dynamic.
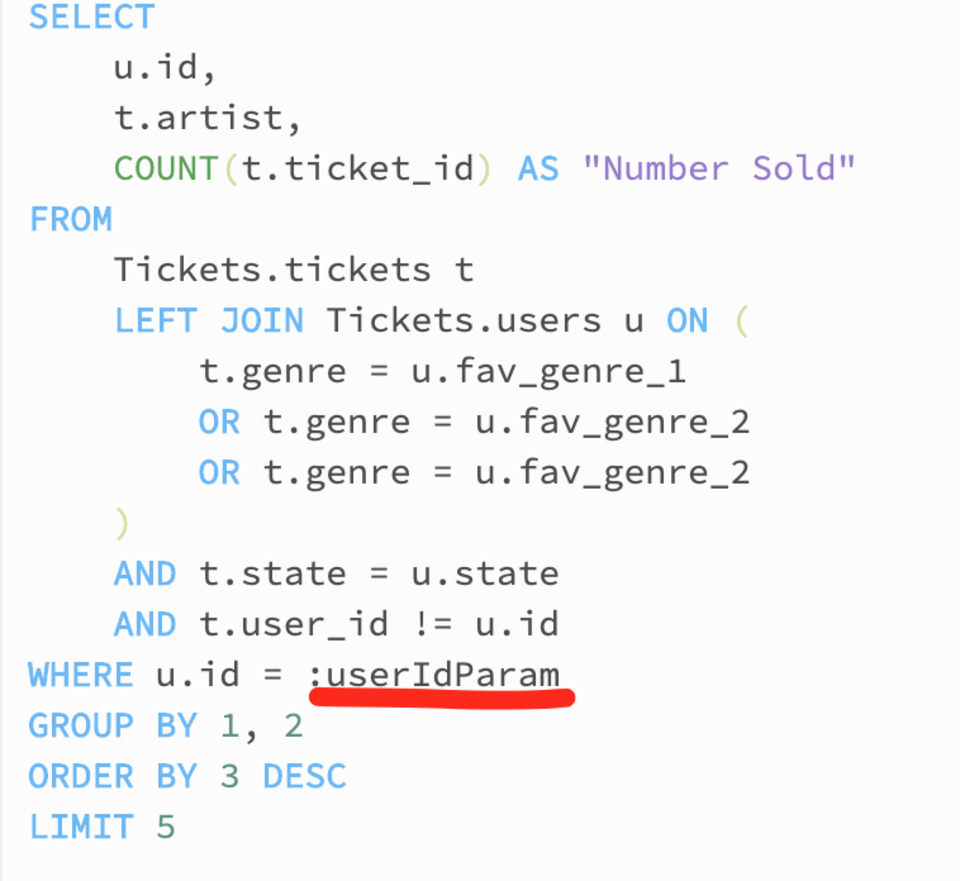 Fig 9. Parameterised where clause
Fig 9. Parameterised where clause
With our statement parameterised, we can now click the Create Query Lambda button above the SQL editor. Give it a name and description and save it. This is now a function we can call to run the SQL for a given user. In the next section I’ll run through using this Lambda via the REST API which would then allow a front end interface to display the results to users.
Recommendations via REST API
To see the Lambda you’ve just created, on the left hand navigation select Query Lambdas and select the Lambda you’ve just created. You’ll be presented with the screen shown in Fig 10.
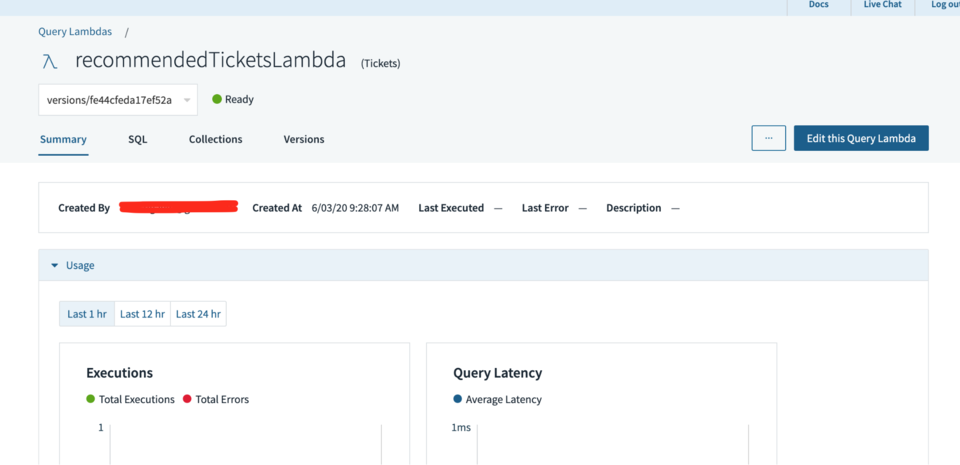 Fig 10. Query Lambda overview
Fig 10. Query Lambda overview
This page shows us details about how often the Lambda has been run and its average latency, we can also edit the Lambda, look at the SQL and also see the version history.
Scrolling down the page we’re also given examples of code that we could use to execute the Lambda. I’m going to take the Curl example and copy it into Postman so we can test it out. Note, you may need to configure the REST API first and get yourself a key setup (in the console on the left navigation go to ‘API Keys’).
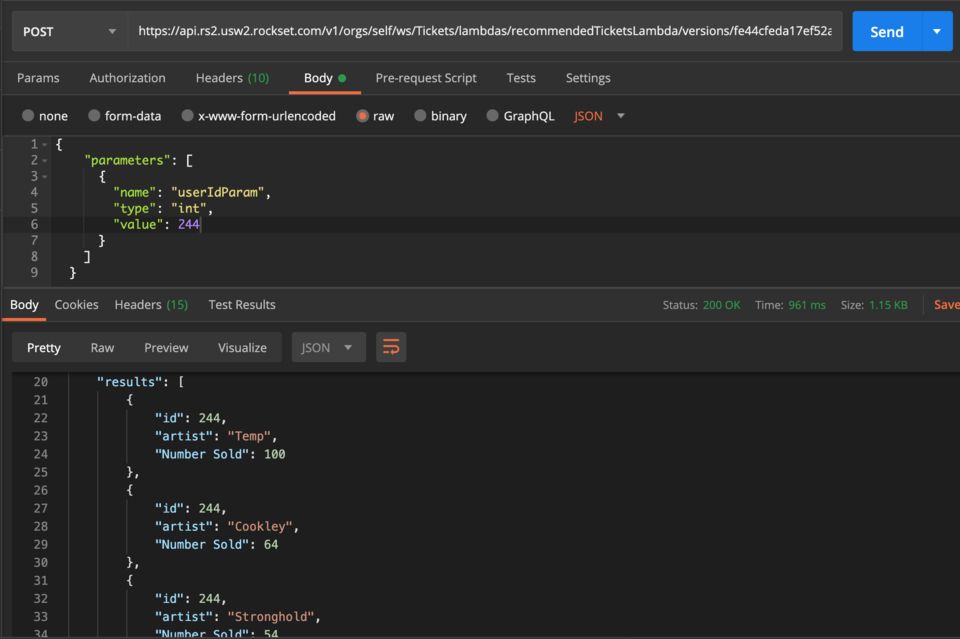 Fig 11. Query Lambda Curl example in Postman
Fig 11. Query Lambda Curl example in Postman
As you can see in Fig 11, I’ve imported the API call into Postman and can simply change the value of the userIdParam within the body, in this case to id 244, and get the results back. As you can see from the results, user 244’s highest recommended artist is ‘Temp’ with 100 tickets sold recently in their state. This could then be displayed to the user when browsing for tickets, or on a homepage that provides recommended tickets.
Conclusion
The beauty of this is that all the work is done by Rockset, freeing up our Mongo instance to deal with large spikes in ticket purchases and user activity. As users continue to purchase tickets, the data is copied over to Rockset in real time and the recommendations for users will therefore be updated in real time too. This means timely and accurate recommendations that will improve overall user experience.
The implementation of the Query Lambda means that the recommendations are available for use immediately and any changes to the underlying functionality of building recommendations can be rolled out to all consumers of the data very quickly, as they are all using the underlying function.
These two features show great improvements over accessing MongoDB directly and give developers more analytical power without affecting core business functionality.