
Why I’m sick of ETL tools and what I use instead (hint, it’s a different ETL tool)
In my previous post I talked about how to architect your data warehouse, especially if you’re using Amazon Redshift.
To build that architecture in practice, we need a tool to Extract, Load and Transform (ETL) our data through the layers. This could be completed using traditional ETL tool such as Informatica, Pentaho, Talend or many more.
These tools are great but you may find that Amazon’s Data Pipeline tool can also do the trick and simplify your workflow.
In this post I’ll outline some of the basics of Data Pipeline and it’s pros and cons vs other ETL tools in the market.
What is Data Pipeline?
Data pipeline is an ETL tool offered in the AWS suite. It has a web based graphical interface that allows you to create pipelines from a number of different building blocks.
These building blocks represent physical nodes; servers, databases, S3 buckets etc and activities; shell commands, SQL scripts, map reduce jobs etc.
You join the blocks together to form a pipeline for your data to flow through. It even comes with some out of the box workflows to bring data into Redshift from S3, Import or Export data to and from DynamoDB using S3 and even run a job on an Elastic Map Reduce (EMR) cluster.
It can do some pretty complex stuff too as demonstrated by Swipely’s workflow in the image below.
](https://cdn-images-1.medium.com/max/800/1*FAJsepvgP0ErOnN7kqZ1gw.jpg)
Data Pipeline vs the market
Infrastructure
Like any other ETL tool, you need some infrastructure in order to run your pipelines.
Where Data Pipeline benefits though, is through its ability to spin up an EC2 server, or even an EMR cluster on the fly for executing tasks in the pipeline.
This inevitably keeps pricing lower as the infrastructure is only in use for the duration of the job, after which it’s destroyed. It also means its a lot easier to get up and running without having to worry about physical infrastructure.
Don’t worry, if you’re worried about the overhead of spinning up servers all the time, you can still get your pipelines to use a “static” EC2 instance or EMR cluster.
Ops
These days, all engineers should care about operations. When building an application, key things like monitoring and alerting as well as infrastructure considerations should be taken into account.
](https://cdn-images-1.medium.com/max/800/1*NO444TAf4KuoxqQ6zTaqgA.jpeg)
Data Pipeline has an in-built alerting capability that utilises amazons simple notification service (SNS). This can be used to send text messages or emails to alert on failure of a specific step, or the whole pipeline.
The service also has the obvious benefit of being accessible from anywhere with an internet connection. Due to the tool being web based, you can access and understand failures away from your work computer and hot fix.
Hugely beneficial if you’re on call to fix important failures, as you can do it from the comfort of your bed via your smartphone :D
Complexity
If you have experience with ETL tools, then using Data Pipeline should be fairly simple. This section wont necessarily talk about the complexity of the tool (as all tools require some sort of learning curve) but the complexity of your use case and how that would fit within Data Pipeline.
In my experience, ETL tools give you a graphical interface to try and simplify performing transformations on data. Whether it’s to simply moving data from one place to another or transform it along the way. You can also build patterns or templates to deal with similar tasks to avoid repeating the same pipelines.
What I’ve always found though is that you almost always end up, in one way or another, reverting back to raw SQL, code or system commands. Most ETL tools provide the capability to do this for those edge cases that are complex within the tool, but once used it defeats the object of the tool.
Now a non technical user requires lower level knowledge in order to understand a transformation.
So lets say it’s technical people building the workflows. They’re perfectly capable of writing SQL which then also defeats the object of the tool. What you end up with now is an unnecessary overhead of using an ETL tool where it’s not needed, that also hosts business logic that no transferable or useable outside of the ETL tool.
SO… what am I rambling on about?
 Breathing intensifies
Breathing intensifies
What I’m trying to say, is that for me as a Data Engineer, I don’t need another tool that will go out of fashion in a few years and is just another overhead.
What I want is something to sit around my SQL scripts, Spark applications, Python transformations or whatever it is I’m building. Something that will help stick these blocks together where necessary, orchestrate and schedule my pipelines and take care of all the “DevOps” stuff too (alerting, logging etc.).
I found that Data Pipeline gives me all of the above.
The components within Data Pipeline are more for scheduling and orchestrating workflows of code or applications that you may have already written; rather than forcing you to conform to the bounds and rules of the chosen ETL application.
The complexity is within your control, you can keep your sql, shell or python script - they all still work here.
What you get is a tool that can schedule when your jobs run and orchestrate where they should run. You also get the benefit of alerting to tell you when things have failed.
In essence, you get a nice cloud based wrapper for your data processing jobs that allows you to retain control and reduce complexity.
And if you ever want to leave — you can just take your code with you and move onto the next trendy thing.
Recommended Posts
How to Build a Fast Data Warehouse with Amazon Redshift
| redshift | | aws | | datawarehouse | | bigdata |
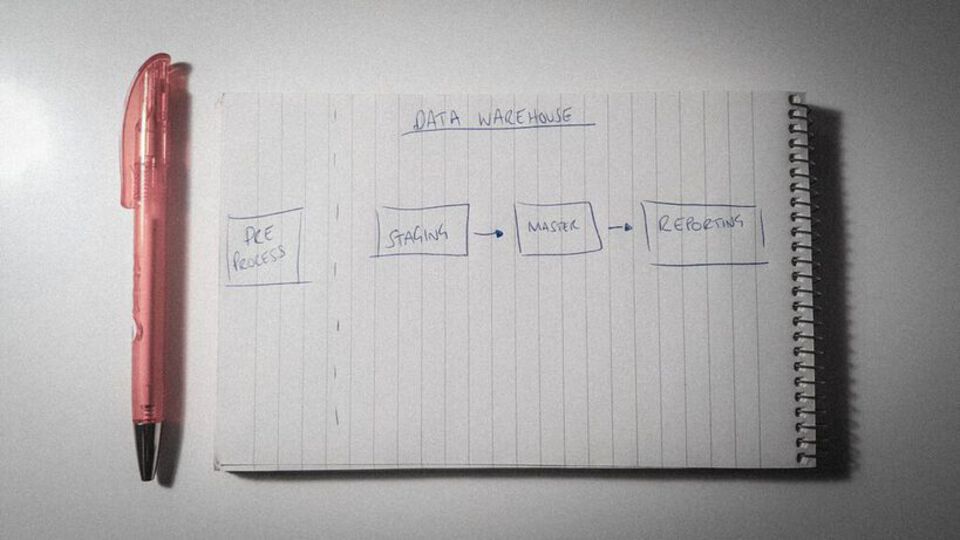 Data Warehousing: Simplified
Data Warehousing: Simplified
5 Tips to Realistically Grow Your Instagram Account
| instagram | | socialmedia |
In June of 2018 I started a little test. I don’t know where the idea came from but it was something that just hit me and made sense.